
Survol du processus de numérisation d'un livre.
Adorons Jésus-Eucharistie! | Accueil >> Varia >> Génie logiciel
Survol du processus de numérisation d'un livre.
Voici un aperçu de la démarche que j'utilise (SVP me le dire si vous avez une meilleure méthode). Chaque étape sera expliquée plus loin:
1.1) Propriété intellectuelle. Avant de rendre public un livre, il faut s'assurer qu'il soit libre de droits, ou que les ayants droits donnent leur permission écrite.
1.2) Photographie numérique («Scanning» en anglais). Un dispositif électronique convertit les pages papier du livre en gros fichiers contenant des photographies brutes de ces pages.
1.3) Reconnaissance Optique de Caractères (ROC). Un logiciel prend les photographies brutes et les interprète du mieux qu'il peut pour transformer les taches d'encre en lettres de l'alphabet.
1.4) Correction. Un réviseur compare l'image brute avec le résultat de la ROC, et fait les corrections nécessaires.
1.5) HTML ou autre encodage. Cette partie de la démarche est variable. Elle peut inclure le formatage du texte (italiques, gras, styles, etc.), l'organisation des éléments logiques (notes de bas de page, table des matières, index, etc.), et les fonctionnalités propres aux livres numériques (hyperliens, animations, etc.).
Idéalement, vous contactez les ayants droits et vous obtenez leur permission écrite. Si vous ne trouvez pas les ayants droits, ou s'ils ne vous répondent pas, essayez au minimum de réunir les «éléments de preuve» qui vous permettraient de montrer à un éventuel tribunal que vous avez fait tout votre possible pour obtenir cette permission. (Voir par exemple la Lettre ouverte à Desclée de Brouwer.)
Voici les étapes:
3.1) Obtenir l'accès à un appareil de balayage numérique («scanneur»). C'est facile, puisque presque n'importe quel dispositif fera l'affaire, incluant d'aller bêtement au bureau de poste le plus proche pour utiliser leur photocopieuse professionnelle. Les photocopieuse de nos jours commencent par scanner les pages qu'elles doivent copier, et peuvent sauvegarder ces pages balayées en PDF ou autres formats, qu'on peut ensuite extraire avec une barrette de mémoire USB. Mon ancien numériseur (Canon Canoscan LiDE 80) était un des modèles les plus simples et les moins dispendieux sur le marché, acheté pour environ 150$ il y plusieurs années. Depuis ce temps, les prix n'ont fait que baisser et les fonctionnalités n'ont fait que monter, alors vous ne pouvez pas vraiment vous tromper! En passant, vous pouvez payer très cher pour une machine équipée d'un alimentateur de documents («automatic document feeder» en anglais), mais selon moi c'est quasiment inutile, car les pages des vieux livres qu'on ne peut plus trouver en librairie (ceux qu'on a tendance à vouloir numériser!) ont souvent des formats et des épaisseurs qui se prêtent peu à la manipulation automatique.
3.2) Obtenir un logiciel de balayage numérique («scanning software»). Souvent, ils viennent avec le dispositif. C'est comme ça que j'ai obtenu mon logiciel ScanSoft Omnipage SE, qui suffisait pour mes besoins. Ce logiciel faisait aussi la ROC, mais je n'ai pas réussi à le faire marcher sous Windows 7. En plus, au 2017-oct-09, il n'était plus disponible, mais d'autres semblent faire le même travail, comme Nuance OmniPage Standard, ABBYY FineReader 14, etc.
3.3) Préparer le livre. Malheureusement, jusqu'à maintenant, j'ai eu de bons résultats en coupant le dos du livre, ce qui sépare toutes les pages et permet de les placer bien à plat sur la platine de lecture de l'analyseur. Une méthode qui fonctionne: (1) couper la couverture; (2) placer le livre au bord de l'établi; (3) disposer une règle de métal près du dos du livre (il faut être assez loin du dos pour que toutes les pages soient libres après la coupe, mais pas trop loin pour ne pas couper des caractères); (4) bien serrer la règle avec deux serres-joints; (5) couper au couteau tout-usage (Xacto, Olfa, etc.); (6) après l'analyse, on peut remettre les feuilles libres «en sandwich» entre le devant et le derrière de la couverture coupée, et faire tenir le tout avec des élastiques. Il faut conserver l'original tant que la numérisation n'est pas terminée. Bien sûr, ne brisez pas le livre s'il ne vous appartient pas! J'ai déjà numérisé un livre sans le couper, mais c'est très désagréable et ne donne pas de bons résultats.
3.4) Faire le balayage numérique en tant que tel. Contrairement aux apparences, c'est une des étapes les plus rapides et agréables, alors profitez-en! En gros, vous démarrez le logiciel et le balayeur, et vous placez les pages manuellement sur la platine de lecture, les unes après les autres. Arrêtez à toutes les 50 pages, et sauvegardez le fichier, au cas où votre logiciel «planterait» (ça m'est arrivé plusieurs fois). Nommez les fichiers selon les pages qu'ils contiennent, comme par exemple «pages 0001 à 0060.opd». Consultez le manuel de votre logiciel de balayage numérique pour les détails.
À la fin de cette étape, certaines personnes crient victoire et laissent tomber ces immenses fichiers sur l'Internet, prétendant que ce livre vient d'être «numérisé». Je trouve que c'est de l'inflation verbale: ce livre vient d'être photographié, pas vraiment numérisé.
Une photographie d'une tache d'encre ayant la forme de la lettre «A» n'est pas la même chose que la lettre «A». La lettre «A» consomme environ 8 bits de mémoire pour l'entreposer (si par exemple vous utilisez ASCII), et l'ordinateur sait exactement ce que sont ces Uns et ces Zéros (la lettre «A»!). Mais la photographie d'une tache d'encre peut consommer d'immenses quantités d'octets, et un ordinateur peut interpréter cette tache d'encre de plusieurs manières, incluant: «Je n'ai pas la moindre idée ce que c'est». Un livre vraiment numérisé exige beaucoup plus de travail, mais il a aussi beaucoup plus d'avantages (comme la compacité, la facilité d'indexage, la facilité de faire des corrections et des ajouts, etc.).
C'est peut-être la partie la plus complèxe de toute cette démarche, mais heureusement cette complexité est cachée à l'intérieur du logiciel de ROC. Vous n'avez qu'à pousser sur un bouton, et l'ordinateur fait (presque!) tout le reste. Le logiciel va vous poser des questions quand il sera incapable de reconnaître certains mots. Dans l'exemple suivant, le logiciel est confondu car il n'y a pas de point sur le «i»:
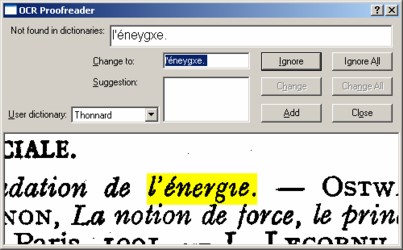
Exemple d'erreur de ROC.
Cette partie de la démarche est celle qui profite normalement des versions plus récentes d'un logiciel de ROC. À la fin du processus de la ROC, le logiciel produit un fichier avec les caractères qu'il a réussi à reconnaître.
C'est aussi la partie de la démarche qui a le plus diminué en importance depuis que j'ai numérisé mes premiers livres. Les logiciels de ROC sont maintenant tellement répandus qu'il devient rare de trouver un livre «vierge», qui n'a jamais été photographié et passé dans un logiciel de ROC (par exemple, Google a traité un très grand nombre de livres anciens avec cette méthode). Essayez-le! Choisissez un livre, dactylographiez une phrase prise au hasard dans un moteur de recherche, et vous le trouverez probablement sur Internet. Je serais aussi prêt à parier que votre bureau de poste local a une photocopieuse qui peut faire la ROC de vos documents automatiquement (même si la dame âgée qui travaille à ce comptoir postal ne le sait peut-être pas).
Je n'ai jamais vu de logiciel de ROC qui évitait toutes les erreurs. D'ailleurs, c'est presque théoriquement impossible (pensez aux pages déchirées ou vandalisées par des gribouillis, ou aux erreurs d'impression, etc.). Il faut lire le fichier texte produit par le logiciel ROC, et le comparer à l'image numérique brute. En pratique, cette étape est faite en deux temps.
5.1) Premier «dégrossissage» plus ou moins automatique. Après la ROC mais avant l'encodage, on utilise les fonctionnalités du logiciel de traitement de texte pour faire le plus de corrections «globales» possible. À titre d'exemple, les livres de Thonnard ne mettent pas d'accents sur le «À» qui commence une phrase, alors on peut faire une recherche semi-automatique et corriger toutes les occurences, etc.
5.2) La correction «monastique». C'est la vraie correction, celle qui est un travail de moine! Moi j'ai tendance à vérifier un paragraphe à la fois, et à intégrer cette étape avec l'étape suivante (voir N° 6.6 ci-bas).
C'est la partie la plus longue et difficile de la démarche, parce qu'on ne fait plus simplement une traduction (d'un format papier à un format électronique), mais une production (on rajoute des choses qui souvent n'étaient même pas dans l'original, comme des styles).
Il y a en théorie au moins trois approches à cette étape:
- sauvegarder le produit de la ROC en tant que fichier HTML, et ajuster le HTML
manquant ou erroné;
- le sauvegarder dans le format d'un traitement de texte ordinaire (comme
Microsoft Word), pour ensuite faire les changements, et finalement utiliser la
fonctionnalité du traitement de texte pour sauvegarder le résultat en format
HTML;
- le sauvegarder en tant que simple fichier texte ASCII, et encoder le HTML à
partir de rien.
J'ai essayé ces trois approches. À ma connaissance, actuellement, c'est moins de travail d'encoder le HTML à partir de rien, si vous voulez faire un travail impeccable. (Bien sûr, de nouvelles versions des logiciels pourraient changer cette conclusion dans l'avenir.)
Voici de quoi pourrait avoir l'air votre écran d'ordinateur pendant que vous faites ce travail:
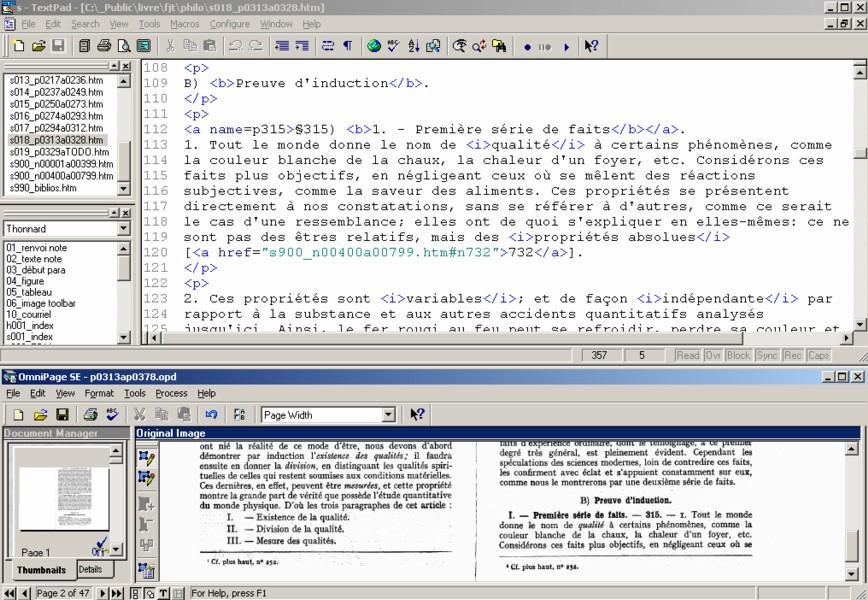
Cliché d'écran lors de l'encodage.
Si vous décidez d'encoder le livre en HTML (ma recommandation actuelle), vous pouvez lire un petit texte à ce sujet (comme par exemple Le HTML pour les grand-mères). Si vous tapez des codes HTML «à la main», vous perdez probablement votre temps. Un bon logiciel de traitement de texte vous permet de noircir le bout de texte que vous voulez encoder (comme par exemple un mot que vous voulez mettre en italique), de taper une combinaison de touches, qui, elle, va lancer une macro qui fera le travail à votre place.
Voici un aperçu des étapes que j'ai utilisé pour numériser le Précis de philosophie de F.-J. Thonnard. (Mais gardez en tête que cette partie de la démarche peut être très variable d'un livre à l'autre, et d'une personne à l'autre):
6.1) Délimitez un paragraphe. J'ai tendance à faire ces étapes paragraphe par paragraphe.
6.2) Rajoutez le formatage à ce paragraphe. Par exemple, mettez en italiques et en gras ce qui l'est dans l'original.
6.3) Rajoutez les notes de bas de page, les hyperliens, etc. Souvent, le logiciel de ROC est incapable de reconnaître de manière fiable les notes de bas de page. Ces temps-ci, je procède ainsi: (1) double-cliquer sur le gabarit de «renvoi de note» dans ma «palette de bribes de texte» (en bas à gauche dans le cliché d'écran ci-haut); (2) couper le texte de la note de bas de page et aller le coller dans la page HTML qui contient toutes les notes; (3) rajouter le gabarit de note de bas de pages («02_texte_note» en bas à gauche dans le cliché d'écran); (4) donner le numéro suivant à la note; (5) revenir à la page d'origine et fixer le même numéro de note de bas de page.
6.4) Refaites ou récupérez les images, photos, dessins, etc..
6.5) Formattez le code HTML. (au goût) On peut lancer une macro qui fait la justification. Ce formatage du code ne paraît pas lorsqu'on lit la page dans un fureteur web, mais c'est plus courtois pour les autres programmeurs qui pourront avoir à modifier votre HTML.
6.6) Faites la correction «monastique» finale. Non seulement vous faites cette correction, mais idéalement, une autre personne que vous fera une deuxième révision de votre travail.
Cet article parle de prendre des livres dans le format parfois appelé «édition de l'Arbre Mort», et les mettre en format numérique ou informatique. Mais nous pouvons poser la question: «Que dire de mettre ce livre dans d'autres formats numériques (il y en a plusieurs à part HTML, comme MS-Word, PDF, ePub, etc.), ou même de remettre cette version numérique dans une édition de l'arbre mort?»
La réponse brève est: sûrement, mais je me cherche encore un logiciel-miracle qui va faire ça correctement et à prix raisonnable.
Une réponse plus longue est: pour mon site web, je pense que HTML est en ce moment le moins mauvais format. Pour les livres qui ne m'appartiennent pas mais qui sont sur mon site web, vous êtes toujours les bienvenus de tout télécharger et faire ce que bon vous semble avec eux, incluant les remettre en édition de l'arbre mort (mais ne présumez pas que les ayants droit vont être gentils avec vous, juste parce que je suis gentil avec vous). Des tests récents que j'ai fait pour un gars qui voulait imprimer le Petit Catéchisme pour les enfants de sa paroisse ont été de juste sélectionner le texte sur la page web et tout coller dans Microsoft Word, ensuite de jouer avec les styles jusqu'à temps que les choses aient l'air acceptable. Je ne pense pas qu'il y ait de l'espoir pour des choses comme les sauts de page (comment pourrais-je savoir d'avance quelle taille de papier vous aller utiliser pour votre édition de l'arbre mort?), la disposition des images (voulez-vous des grosses images, des petites, rien du tout? à gauche avec le texte qui coule autour, à droite avec le texte en haut et en bas mais pas autour? etc.), la table des matières (combien de niveaux de la hiérarchie voulez-vous inclure?), les notes (au pied de la page? à la fin du chapitre ou du livre?), etc. Mais les styles CSS que j'utilise dans mon encodage HTML semblent aider Microsoft Word produire un résultat assez utilisable. Et normalement, une fois converti en MS-Word, vous pouvez aller de là au PDF, ePub, etc.
(Si je peux me permettre un commentaire personnel sur des efforts pour mettre des livres sur mon site web en format papier ou autre, en pensant ainsi leur donner un plus grand rayonnement, je vous félicite pour vos bonnes intentions, mais je suis plutôt pessimiste. La plupart des gens aiment leur ignorance.)
Tom Gilb dit: «Si vous ne savez pas ce que vous faites, ne le faites pas à grande échelle», et Jon Bently rajoute: «C'est plus rapide de faire un miroir de téléscope de 4 pouces, pour ensuite en faire un de 6 pouces, que d'essayer de faire un miroir de 6 pouces tout de suite en partant».
J'ai eu la chance d'appliquer ces conseils à la numérisation des livres. J'ai commencé avec un petit livre simple de 20 pages par Courtois, ensuite j'ai fait un livre de 200 pages par Sertillanges, et c'est seulement alors que je me suis attaqué au livre que je voulais vraiment numériser, un monstre de 2000 pages de Thonnard. Je recommande fortement que vous suiviez un cheminement semblable.
Adorons Jésus-Eucharistie! | Accueil >> Varia >> Génie logiciel